

Bạn muốn tìm hiểu Stable Diffusion? Hướng dẫn dành cho người mới bắt đầu này dành cho người mới chưa có kinh nghiệm với Stable Diffusion hoặc các trình tạo hình ảnh AI khác.
Bạn sẽ có cái nhìn tổng quan về Stable Diffusion và một số mẹo cơ bản để sử dụng nó.
Hãy dùng thử Stable Diffusion ngay trên trang này. Đó là cách tốt nhất để học!
Đây là phần đầu tiên của loạt hướng dẫn dành cho người mới bắt đầu.
Đọc phần 2: Cấu Trúc Câu Lệnh
Đọc phần 3: Inpainting.
Đọc phần 4: Models
Nội dung
- Stable Diffusion AI
- Stable Diffusion online demo
- Tôi có thể tạo loại hình ảnh nào với Stable Diffusion?
- Phong cách hoạt hình
- Ảnh thực tế
- Phong cảnh
- tưởng tượng
- Phong cách nghệ thuật
- Động vật
- Đăng ký cho tôi! Làm thế nào để bắt đầu tạo hình ảnh?
- Trình tạo trực tuyến
- GUI nâng cao
- Làm thế nào để xây dựng một lời nhắc tốt?
- Quy tắc ngón tay cái để xây dựng lời nhắc tốt
- Sử dụng các từ khóa mạnh mẽ
- Hãy chi tiết và cụ thể
- Những thông số đó là gì và tôi có nên thay đổi chúng không?
- Tôi nên tạo bao nhiêu hình ảnh?
- Hình ảnh đến hình ảnh là gì?Common ways to fix defects in images
- Sửa các đồ tạo tác nhỏ bằng inpainting
- Phục hồi khuôn mặt
- Mô hình tùy chỉnh là gì?
- Tôi nên sử dụng mô hình nào?
- Làm thế nào để đào tạo một mô hình mới?
- Câu Lệnh Âm
- Cách tạo bản in lớn với Stable Diffusion?
- Làm cách nào để kiểm soát bố cục hình ảnh?
- Hình ảnh đến hình ảnh
- ControlNet
- Nhắc khu vực
- Độ sâu hình ảnh
- Tạo các chủ đề cụ thể
- Người thực tế
- Động vật
- Bạn có thể làm video với Stable Diffusion được không?
- Bước tiếp theo
Stable Diffusion AI
Stable Diffusion AI
là một mô hình AI khuếch tán tiềm ẩn tạo ra những hình ảnh đẹp mắt về mặt thẩm mỹ. Các hình ảnh có thể chân thực như ảnh được chụp bằng máy ảnh hoặc theo phong cách nghệ thuật như thể được tạo ra bởi một nghệ sĩ chuyên nghiệp.
Phần tốt nhất: nó được cung cấp miễn phí cho tất cả mọi người và nó được xây dựng để tăng tốc — bạn thậm chí có thể chạy nó trên máy tính của riêng mình.
Cách sử dụng Stable Diffusion? Bạn cần một lời nhắc mô tả một hình ảnh. Ví dụ:
gingerbread house, diorama, in focus, white background, toast , crunch cereal
Lời nhắc này tạo ra các hình ảnh sau đây.






Có các dịch vụ tạo văn bản thành hình ảnh tương tự như DALLE và MidJourney. Tại sao Stable Diffusion? Ưu điểm của Stable Diffusion là
- Mã nguồn mở: Nhiều người đam mê đã tạo ra các công cụ miễn phí và mạnh mẽ.
- Được thiết kế cho các máy tính có công suất thấp: Chạy miễn phí hoặc giá rẻ.
Stable Diffusion bản trình diễn trực tuyến
Cách tốt nhất để hiểu về Stable Diffusion là tự mình dùng thử.
Hãy thử trình tạo hình ảnhStable Diffusion bên dưới. Dưới đây là bốn bước đơn giản.
- Nhắm mắt lại.
- Hãy tưởng tượng một hình ảnh bạn muốn thực hiện.
- Mô tả hình ảnh bằng lời càng chi tiết càng tốt. (Để có kết quả tốt nhất, hãy đảm bảo bao phủ chủ thể và hậu cảnh và sử dụng nhiều từ mô tả)
- Viết nó vào hộp nhập dấu nhắc bên dưới.
Bạn có thể giữ nguyên dấu nhắc phủ định.
Dưới đây là danh sách các ví dụ đơn giản về lời nhắc mà bạn có thể thử.
a cute Siberian cat running on a beach
a cyborg in style of van Gogh
french-bulldog warrior on a field, digital art, attractive, beautiful, intricate details, detailed face, hyper-detailed closed eyes,zorro eye mask, artstation, ambient light
Chuyển đổi mô hình để xem hiệu ứng. Bạn sẽ tìm hiểu về các mô hình trong phần cuối của hướng dẫn này.
- Stable Diffusion v1.5: Mô hình cơ sở chính thức. Linh hoạt trong tất cả các phong cách.
- Realistic Vision v2.0: Xuất sắc trong việc tạo ra các hình ảnh thực tế theo phong cách ảnh.
- Anything v3.0: Phong cách hoạt hình.
Bạn có thể nhận thấy rằng các hình ảnh có thể bị đánh hoặc trượt. Đừng lo lắng; có nhiều cách bạn có thể cải thiện hình ảnh. Đọc tiếp.
Tôi có thể tạo loại hình ảnh nào với Stable Diffusion?
Bầu trời là giới hạn! Dưới đây là một số ví dụ.
Anime style






Photo-realistic






Tìm hiểu làm thế nào để tạo ra những người thực tế như thế này.
Landscape




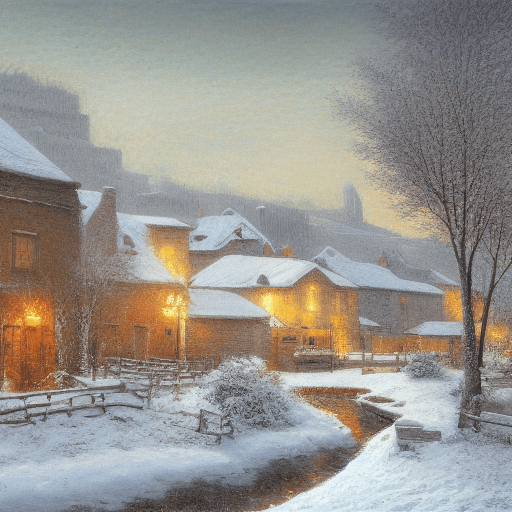

Fantasy






Artistic styles






Động vật







Tìm hiểu làm thế nào để tạo ra động vật.
Đăng ký Stable Diffusion ! Làm thế nào để bắt đầu tạo hình ảnh?
Trình tạo trực tuyến
Đối với những người hoàn toàn mới bắt đầu, tôi khuyên bạn nên sử dụng trình tạo trực tuyến miễn phí ở trên hoặc các dịch vụ trực tuyến khác. Bạn có thể bắt đầu tạo mà không gặp rắc rối khi thiết lập mọi thứ.
Giao diện người dùng đồ họa nâng cao
Nhược điểm của các trình tạo trực tuyến miễn phí là các chức năng khá hạn chế.
Bạn có thể sử dụng GUI (Giao diện người dùng) nâng cao hơn nếu bạn phát triển nhanh hơn chúng. Tôi sử dụng AUTOMATIC1111, một lựa chọn mạnh mẽ và phổ biến. Xem Hướng dẫn bắt đầu nhanh để thiết lập trong máy chủ đám mây Google Colab.
Chạy trên PC của bạn cũng là một lựa chọn tốt nếu bạn có GPU NVIDIA tốt với ít nhất 4GB VRAM. Xem hướng dẫn cài đặt cho Windows và Mac.
Tại sao nên sử dụng GUI nâng cao? Một loạt các công cụ theo ý của bạn
- Kỹ thuật gợi ý nâng cao
- Tái tạo một phần nhỏ của hình ảnh với Inpainting
- Tạo hình ảnh dựa trên hình ảnh đầu vào (Image-to-image)
- Chỉnh sửa một hình ảnh bằng cách nói một hướng dẫn.
Làm thế nào để xây dựng một lời nhắc tốt?
Có rất nhiều điều cần học để tạo ra một dấu nhắc tốt. Nhưng điều cơ bản là mô tả chủ đề của bạn càng chi tiết càng tốt. Đảm bảo bao gồm các từ khóa mạnh mẽ để xác định phong cách.
Sử dụng trình tạo lời nhắc là một cách tuyệt vời để tìm hiểu quy trình từng bước và các từ khóa quan trọng. Điều cần thiết cho người mới bắt đầu là tìm hiểu một tập hợp các từ khóa mạnh mẽ và tác dụng mong đợi của chúng. Điều này giống như học từ vựng cho một ngôn ngữ mới. Bạn cũng có thể tìm thấy một danh sách ngắn các từ khóa và ghi chú tại đây.
Một lối tắt để tạo hình ảnh chất lượng cao là sử dụng lại lời nhắc hiện có. Đi tới bộ sưu tập lời nhắc, chọn một hình ảnh bạn thích và đánh cắp lời nhắc! Nhược điểm là bạn có thể không hiểu tại sao nó tạo ra hình ảnh chất lượng cao. Đọc ghi chú và thay đổi lời nhắc để thấy tác dụng.
Ngoài ra, hãy sử dụng các trang web thu thập hình ảnh như Playground AI. Chọn một hình ảnh bạn thích và phối lại lời nhắc. Nhưng nó có thể giống như mò kim đáy bể để có được lời nhắc chất lượng cao.
Coi lời nhắc như một điểm bắt đầu. Sửa đổi cho phù hợp với nhu cầu của bạn.
Quy tắc ngón tay cái để xây dựng lời nhắc tốt
Hai quy tắc: (1) Chi tiết và cụ thể, và (2) sử dụng các từ khóa mạnh mẽ.
Hãy chi tiết và cụ thể
Mặc dù AI tiến bộ vượt bậc, nhưng Khuếch tán ổn định vẫn không thể đọc được suy nghĩ của bạn. Bạn cần mô tả hình ảnh của mình càng chi tiết càng tốt.
Giả sử bạn muốn tạo ảnh một người phụ nữ trong cảnh đường phố. Một lời nhắc đơn giản
a woman on street
cung cấp cho bạn một hình ảnh như thế này:
Chà, bạn có thể không muốn tạo ra một bà, nhưng về mặt kỹ thuật, điều này phù hợp với lời nhắc của bạn. Bạn không thể đổ lỗi cho Stable Diffusion…
Vì vậy, thay vào đó, bạn nên viết nhiều hơn.
a young lady, brown eyes, highlights in hair, smile, wearing stylish business casual attire, sitting outside, quiet city street, rim lighting

Xem sự khác biệt lớn. Vì vậy, hãy rèn luyện kỹ năng xây dựng nhanh chóng của bạn!
Sử dụng các từ khóa mạnh mẽ
Một số từ khóa mạnh hơn những từ khóa khác. Ví dụ là
- Tên người nổi tiếng (ví dụ: Emma Watson)
- Tên nghệ sĩ (ví dụ: van Gogh)
- Phương tiện nghệ thuật (ví dụ: minh họa, hội họa, ảnh)
Sử dụng chúng một cách cẩn thận có thể điều khiển hình ảnh theo hướng bạn muốn.
Bạn có thể tìm hiểu thêm về cách tạo lời nhắc và các từ khóa ví dụ trong kiến thức cơ bản về cách tạo lời nhắc.
Muốn gian lận? Giống như làm bài tập về nhà, bạn có thể sử dụng ChatGPT để tạo lời nhắc!
Những thông số đó là gì và tôi có nên thay đổi chúng không?
Hầu hết các trình tạo trực tuyến đều cho phép bạn thay đổi một số tham số giới hạn. Dưới đây là một số điều quan trọng:
- Kích thước hình ảnh: Kích thước của hình ảnh đầu ra. Kích thước tiêu chuẩn là 512 × 512 pixel. Thay đổi nó thành kích thước dọc hoặc ngang có thể có tác động lớn đến hình ảnh. Ví dụ: sử dụng kích thước dọc để tạo hình ảnh toàn thân.
- Các bước lấy mẫu: Sử dụng ít nhất 20 bước. Tăng nếu bạn thấy một hình ảnh mờ.
- Thang đo CFG: Giá trị điển hình là 7. Tăng lên nếu bạn muốn hình ảnh bị ảnh hưởng nhiều hơn bởi câu lệnh
- Seed: -1 tạo một hình ảnh ngẫu nhiên. Chỉ định một giá trị nếu bạn muốn có cùng một hình ảnh.
Xem các đề xuất cho các cài đặt khác.

Tôi nên tạo bao nhiêu hình ảnh?
Bạn phải luôn tạo nhiều hình ảnh khi kiểm tra lời nhắc.
Tôi tạo 2-4 hình ảnh cùng lúc khi thực hiện các thay đổi lớn đối với lời nhắc để tôi có thể tăng tốc độ tìm kiếm. Tôi sẽ tạo 4 cái cùng lúc khi thực hiện các thay đổi nhỏ để tăng cơ hội nhìn thấy thứ gì đó có thể sử dụng được.
Một số lời nhắc chỉ hoạt động một nửa thời gian hoặc ít hơn. Vì vậy, đừng viết lời nhắc dựa trên một hình ảnh.
Hình ảnh đến hình ảnh là gì?


Image-to-image tạo cơ sở hình ảnh dựa trên hình ảnh đầu vào và lời nhắc.
Image-to-image (hay gọi tắt là img2img) lấy (1) hình ảnh và (2) lời nhắc làm đầu vào. Bạn có thể hướng dẫn tạo hình ảnh không chỉ bằng lời nhắc mà còn bằng hình ảnh.
Trên thực tế, bạn có thể xem văn bản thành hình ảnh là một trường hợp cụ thể của hình ảnh tới hình ảnh: Nó chỉ đơn giản là hình ảnh tới hình ảnh với hình ảnh đầu vào có nhiễu ngẫu nhiên.
Img2img là một kỹ thuật không được đánh giá cao. Xem cách bạn có thể tạo các bản vẽ chuyên nghiệp và hoạt hình hóa ảnh với img2img!
Các cách phổ biến để sửa lỗi trong hình ảnh
Khi bạn nhìn thấy những hình ảnh AI tuyệt đẹp được chia sẻ trên mạng xã hội, rất có thể chúng đã trải qua một loạt các bước xử lý hậu kỳ. Chúng ta sẽ đi qua một số trong số họ trong phần này.
Phục hồi khuôn mặt


Trái: Hình ảnh gốc. Đúng: Sau khi phục hồi khuôn mặt.
Nó nổi tiếng trong cộng đồng nghệ sĩ AI rằng Stable Diffusionkhông giỏi trong việc tạo khuôn mặt. Rất thường xuyên, các khuôn mặt được tạo ra có đồ tạo tác.
Chúng tôi thường sử dụng các mô hình AI hình ảnh được đào tạo để khôi phục khuôn mặt, chẳng hạn như CodeFormer, AUTOMATIC1111 GUI có hỗ trợ tích hợp. Xem làm thế nào để bật nó lên.
Bạn có biết có bản cập nhật cho các mẫu v1.4 và v1.5 để sửa mắt không? Kiểm tra làm thế nào để cài đặt một VAE.
Sửa các đồ tạo tác nhỏ bằng inpainting
Rất khó để có được hình ảnh bạn muốn trong lần thử đầu tiên. Một cách tiếp cận tốt hơn là tạo ra một hình ảnh có bố cục tốt. Sau đó sửa chữa các khiếm khuyết bằng sơn trong.
Dưới đây là một ví dụ về hình ảnh trước và sau khi inpainting. Sử dụng lời nhắc ban đầu để inpainting hoạt động 90% thời gian.

Trái: Ảnh gốc có khuyết điểm. Đúng: Khuôn mặt và cánh tay được cố định bằng sơn trong.Có những kỹ thuật khác để sửa chữa mọi thứ.
Đọc thêm về khắc phục các vấn đề phổ biến.
Mô hình tùy chỉnh là gì?
Các mô hình chính thức do Stability AI và các đối tác của họ phát hành được gọi là các mô hình cơ sở. Một số ví dụ về các mô hình cơ sở là Stable Diffusion 1.4, 1.5, 2.0 và 2.1.
Các mô hình tùy chỉnh được đào tạo từ các mô hình cơ sở. Hiện tại hầu hết các model đều được đào tạo từ v1.4 hoặc v1.5. Chúng được đào tạo với dữ liệu bổ sung để tạo hình ảnh về các kiểu hoặc đối tượng cụ thể.
Chỉ có bầu trời là giới hạn khi nói đến các mô hình tùy chỉnh. Nó có thể là phong cách anime, phong cách Disney, phong cách của một AI khác. Bạn đặt tên cho nó.
Dưới đây là so sánh của 5 mô hình khác nhau.
 Hình ảnh được tạo bởi 5 mô hình khác nhau.
Hình ảnh được tạo bởi 5 mô hình khác nhau.
Cũng dễ dàng hợp nhất hai mô hình để tạo ra một phong cách ở giữa.
Tôi nên sử dụng mô hình nào?
Gắn bó với các mô hình cơ sở nếu bạn đang bắt đầu. Có rất nhiều thứ để học và chơi khiến bạn bận rộn trong nhiều tháng.
Hai nhóm mô hình cơ sở chính là v1 và v2. các mẫu v1 là 1.4 và 1.5. mô hình v2 là 2.0 và 2.1.
Bạn có thể nghĩ rằng mình nên bắt đầu với các mẫu v2 mới hơn. Mọi người vẫn đang cố gắng tìm ra cách sử dụng các mô hình v2. Hình ảnh từ v2 không nhất thiết phải tốt hơn v1.
Tôi khuyên bạn nên sử dụng mô hình v1.5 nếu bạn chưa quen với Stable Diffusion
Làm thế nào để đào tạo một mô hình mới?
Một lợi thế của việc sử dụng Stable Diffusion là bạn có toàn quyền kiểm soát mô hình. Bạn có thể tạo mô hình của riêng bạn với một phong cách độc đáo nếu bạn muốn. Hai cách chính để đào tạo mô hình: (1) Dreambooth và (2) nhúng.
Dreambooth được coi là mạnh mẽ hơn vì nó tinh chỉnh trọng lượng của toàn bộ mô hình. Phần nhúng không ảnh hưởng đến mô hình nhưng tìm các từ khóa để mô tả chủ đề hoặc phong cách mới.
Bạn có thể thử nghiệm với Colab notebook trong bài viết dreambooth.
Câu lệnh Âm
Bạn đặt những gì bạn muốn xem trong lời nhắc. Bạn đặt những gì bạn không muốn thấy trong lời nhắc phủ định. Không phải tất cả các dịch vụ Stable Diffusion đều hỗ trợ lời nhắc tiêu cực. Nhưng nó có giá trị đối với các mẫu v1 và phải có đối với các mẫu v2. Người mới bắt đầu sử dụng lời nhắc tiêu cực phổ biến không hại gì. Đọc thêm về lời nhắc tiêu cực:
- Dấu nhắc tiêu cực hoạt động như thế nào?
- Làm thế nào để sử dụng lời nhắc tiêu cực?
Làm cách nào để tạo các bản in lớn với Stable Diffusion?
Stable Diffusion độ phân giải gốc của là 512×512 pixel cho các kiểu máy v1. Bạn KHÔNG nên tạo hình ảnh có chiều rộng và chiều cao chênh lệch quá nhiều so với 512 pixel. Sử dụng các cài đặt kích thước sau để tạo hình ảnh ban đầu.
- Hình ảnh ngang: Đặt chiều cao thành 512 pixel. Đặt chiều rộng thành cao hơn, ví dụ: 768 pixel (tỷ lệ khung hình 2:3)
- Hình ảnh dọc: Đặt chiều rộng thành 512 pixel. Đặt chiều cao thành cao hơn, ví dụ: 768 pixel (tỷ lệ khung hình 3:2)
Bạn sẽ thấy các đối tượng trùng lặp nếu bạn đặt chiều rộng và chiều cao ban đầu quá cao.
Bước tiếp theo là nâng cấp hình ảnh. GUI AUTOMATIC1111 miễn phí đi kèm với một số trình nâng cấp AI phổ biến.
- Đọc hướng dẫn này để biết hướng dẫn dành cho người mới bắt đầu về công cụ nâng cấp AI.
- Đọc hướng dẫn này để biết cách sử dụng nâng cao hơn.
Làm cách nào để kiểm soát bố cục hình ảnh?
Stable Diffusion công nghệ đang được cải thiện nhanh chóng. Có một số cách.
Hình ảnh đến hình ảnh
Bạn có thể yêu cầu Stable Diffusion để theo sát một hình ảnh đầu vào khi tạo một hình ảnh mới. Nó được gọi là hình ảnh với hình ảnh. Dưới đây là một ví dụ về việc sử dụng hình ảnh đầu vào của một con đại bàng để tạo ra một con rồng. Thành phần của hình ảnh đầu ra tuân theo đầu vào.


Hình ảnh đầu vào

Hình ảnh đầu ra
ControlNet
ControlNet tương tự sử dụng một hình ảnh đầu vào để định hướng đầu ra. Nhưng nó có thể trích xuất thông tin cụ thể, chẳng hạn như tư thế của con người. Dưới đây là một ví dụ về việc sử dụng ControlNet để sao chép tư thế người từ hình ảnh đầu vào.


Hình ảnh đầu vào

Hình ảnh đầu ra
Ngoài các tư thế của con người, ControlNet có thể trích xuất thông tin khác, chẳng hạn như đường viền.
Nhắc khu vực
Bạn có thể chỉ định lời nhắc cho các phần nhất định của hình ảnh bằng cách sử dụng tiện ích mở rộng có tên là Nhắc khu vực. Kỹ thuật này rất hữu ích để chỉ vẽ các đối tượng trong một số phần nhất định của hình ảnh.
Dưới đây là một ví dụ về việc đặt một con sói ở góc dưới cùng bên trái và đầu lâu ở góc dưới cùng bên phải.
Đọc hướng dẫn của Prompter khu vực để tìm hiểu thêm về cách sử dụng nó.
Độ sâu hình ảnh
Depth-to-image là một cách khác để kiểm soát bố cục thông qua hình ảnh đầu vào. Nó có thể phát hiện tiền cảnh và hậu cảnh của hình ảnh đầu vào. Hình ảnh đầu ra sẽ theo cùng một nền trước và nền sau. Dưới đây là một ví dụ.

 Hình ảnh đầu vào
Hình ảnh đầu vào
 Hình ảnh đầu ra
Hình ảnh đầu ra
Tạo các chủ đề cụ thể
Người thực tế
Bạn có thể sử dụng Stable Diffusion để tạo ra những người thực tế theo phong cách ảnh. Hãy xem một số mẫu.








Nó phụ thuộc vào việc sử dụng đúng lời nhắc và mô hình đặc biệt được đào tạo để tạo ra những con người thực tế theo phong cách ảnh. Tìm hiểu thêm trong hướng dẫn để tạo ra những người thực tế.
Động vật
Động vật là chủ đề phổ biến trong số người dùng. Stable Diffusion
Dưới đây là một số mẫu.




Đọc hướng dẫn tạo động vật để tìm hiểu cách thực hiện.
Bạn có thể làm video với Stable Diffusion?
Đúng! Một cách phổ biến để tạo video với Stable Diffusion
là Deforum. Bạn có thể đã nhìn thấy một trong số họ trên phương tiện truyền thông xã hội.
Nó trông như thế này.